TheHive has evolved significantly since its first release in 2016. What began as an open source solution for collaborative incident response quickly became a trusted platform for SOCs and CSIRTs worldwide. Over the years, TheHive gained a vibrant community and a reputation for its flexibility, performance, and integration capabilities.
Key Milestones in TheHive’s Journey
2016: Initial release of TheHive v1, focusing on collaborative investigation and response
2017–2018: TheHive 2 and Cortex integration bring powerful automation and enrichment
2019: TheHive 3 reaches maturity and widespread adoption
2020: Release of TheHive 4 with native multi-tenancy and modernized architecture
2021: Launch of TheHive 5, marking a new era — developed and maintained by StrangeBee, the company founded by TheHive’s creators to support long-term sustainability and innovation
Dec 31, 2021: TheHive 3 reaches End-of-Life (EOL)
Dec 31, 2022: TheHive 4 reaches End-of-Support (EOS)
July 2025 : TheHive 3 & 4 — End of Public Access
TheHive 3 and TheHive 4 are no longer maintained, distributed, or publicly accessible. GitHub repositories for these versions have been archived, and packages are no longer available for download.
This change reflects our focus on the latest generation of TheHive: a commercial solution offering enhanced performance, robust security, and features tailored for modern SOC operations.
From Community Favorite to Enterprise Powerhouse: TheHive 5
TheHive is now distributed exclusively as a commercial product through StrangeBee. Backed by the same team that initiated the project, the latest version continues to evolve with a clear mission: empower security operations centers with reliable, efficient, and future-proof tooling.
Curious about what the new generation of TheHive can do?
We are proud and excited to annonce the availability of TheHive v4.1.0. This release is the new beginning of TheHive’s future, because all the upcoming features and enhancements will be based on this version, without the brakes.
4.1.0 is out after a significant work done during the last 6 months, interrupted by multiple events like:
supporting ES 7 in TheHive 3 and Cortex
supporting ES 7.11 in TheHive 3 and Cortex
5 patch releases of TheHive 4.0
recent OVH datacenter incident (but this one was quickly fixed)
Our community is waiting for it, as we announced it will fix the performance issues that many of you were facing. The reason is that TheHive 4.0.x doesn’t include a database indexation component resulting on poor data fetching performance.
We are glad about this release, it includes tons of new features and improvements, across all the application.
The first and maybe, the main one, is the database indexation (#1731) that will significantly improve performance of queries such as lists, filters and sorting. As a consequence, you should experience a smoother browsing and usage of the application.
Amongst all other news features, we introduced:
Support for MISP taxonomies, in addition to custom tags and tag colour support;
Support for Case TTPs specified by MITRE ATT&CK framework;
Better and improved Case merging and deleting capabilities;
A customisable date and time format
A refined Case Templates management UI
Enhanced Case list UI with bulk actions
Enhanced Task list UI with bulk actions
A platform status page to get an overview of the platform health
Support for migration from TheHive 3.5.1 to 4.1
Support for authentication on Webhook endpoints
For those of you who want to know the full details, here is the change log
A word about the documentation
As you might know, TheHive has a documentation repository that includes content for TheHive 3 and TheHive 4, but the structure needs to be redefined. For that reason, we introduced a new documentation website that aims to be the single starting point of all the docs we produce for TheHive Projects’ products.
In the upcoming days, we will mark the old docs repositories as ARCHIVED and we will maintain the new docs repository.
Until now, we knew TheHive suffered from a performance issue with the database.
Technically, TheHive uses basic index mechanism embedded in JanusGraph. This indexes are simple to use and manage but they contain limitations. They only support equality lookups and cannot be used for sort (for example, this is not possible to simply look for cases with severity > LOW) . However, within TheHive, almost all lists – lists of cases, lists of alerts, tasks …- are sorted. So, getting a list means a scan of all the elements of the list, which have a heavy performance impact, particularly if the list is long.
In order to solve this issue, TheHive 4.1.0 comes with a new index engine, and indexes have to be stored outside the database. As a consequence you need to define and setup dedicated storage for these indexes.
If TheHive is used in a cluster mode, all servers must connect to a common index engine, which can be in a cluster mode or not. In this case, a new component must be installed for index management. Elasticsearch should be used, only as an index engine. For clusters, Elasticsearch is not used like it was with TheHive 3.x when it stored data.
If TheHive is used on a standalone server, Elasticsearch can be used, but a file based index engine – Lucene – can be preferred. The latter solution has less infrastructure impact – no component to install – and only requires configuration that indicate where index data is stored in the filesystem.
For more details about database indexing configuration, please refer to the documentation
MISP taxonomies support
TheHive 4 handles tags in a completely different way than TheHive 3, even if the APIs are still considering tags as simple strings. For example when you create a Case from TheHiv4py, you specify tags as a simple array of strings.
Behind the scene, TheHive transforms the tags into objects, with a namespace, a predicate and an empty value. For example if your create a case with a free tag src=mailbox, TheHive 4 creates a new Tag object as following:
This is where we introduced the support of MISP Taxonomies, allowing admin users with `manageTaxonomy` permission, to import tags defined in machinetag.json format, from the “Administration > Taxonomies page”
Taxonomies import dialog
Note: importing the full MISP taxonomies library can take some time (1 minute)
Once imported, you need to enable the taxonomies you need for use cases. All the taxonomies are disables by default. Enabling a taxonomy, make its tags available to all the organisations on the platform, so analysts can use the to tag Cases, Alerts, Observables.
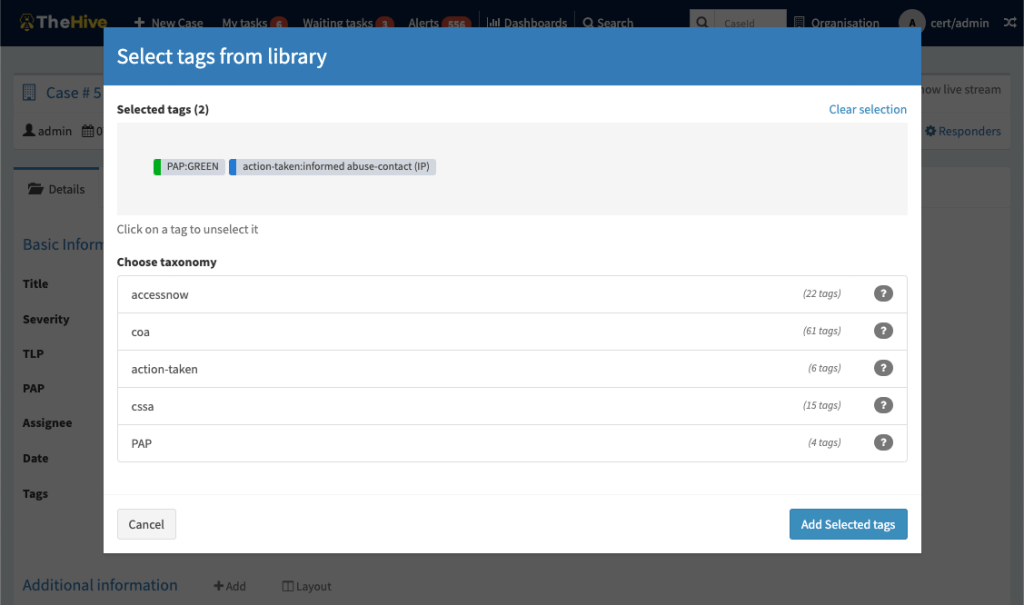
Tags selector
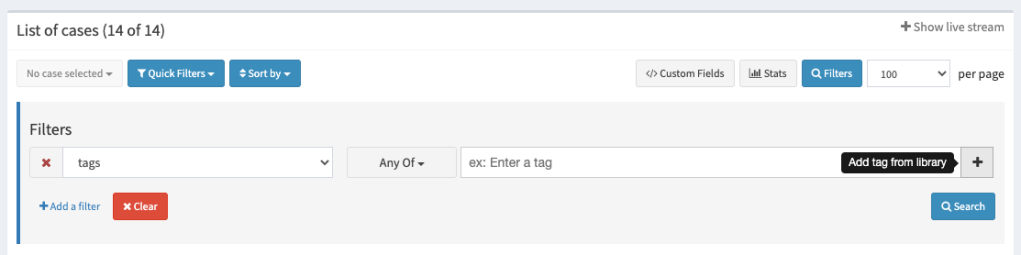
Taxonomy tags can also bee used from any tag filter in Case, Alert and Observable lists:
Tag filter
Custom tags support
Custom tags or free tags, is the way we call free text tags associated with TheHive objects. Internally, custom tags are included into organisation related spécial taxonomy called `freetags`.
Custom tags are not shared across organisations, so existing users defining sensitive data in tags won’t suffer any data leakage issue.
In general, custom tags in TheHive are not supposed to user data and information. It’s not a best practice to use email adresses as tags. Custom fields are the right place for this type of data.
This topic needs a dedicated blog post, to share the best practices of using tags.
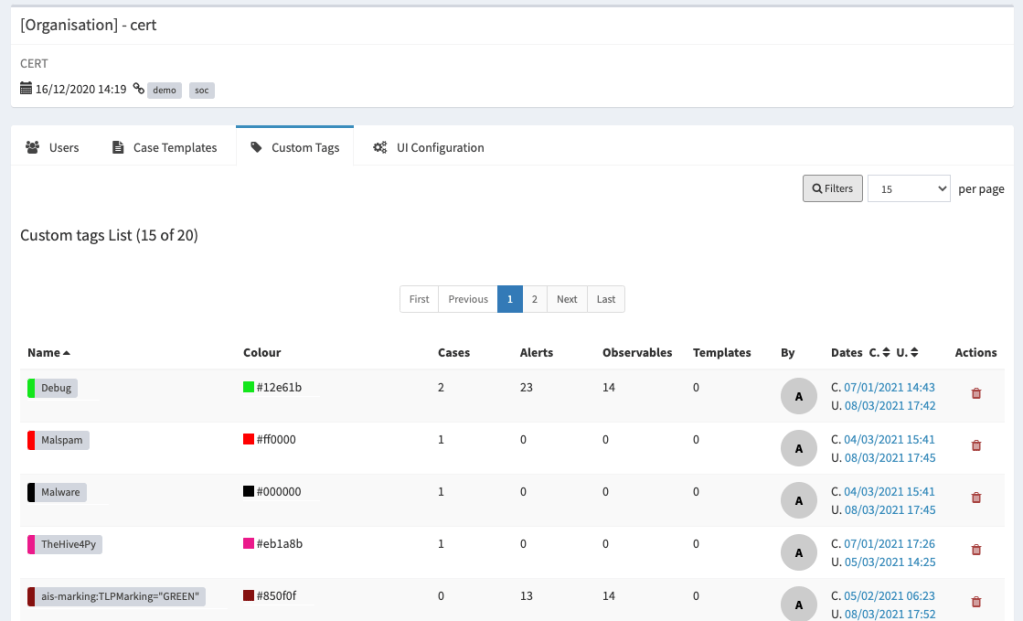
So, how do an org admin manage the custom tags? Well, TheHive 4.1 comes with a new UI section, under the organisation management page, allowing:
Listing all the custom tags
Filtering and sorting
Updating custom tag values and colours
Deleting custom tags
Displaying custom tag usage (# of cases, # of alerts, # of observables and # of case templates)
Custom tags management
For users migrating from TheHive 3, all the existing tags are imported as custom tags
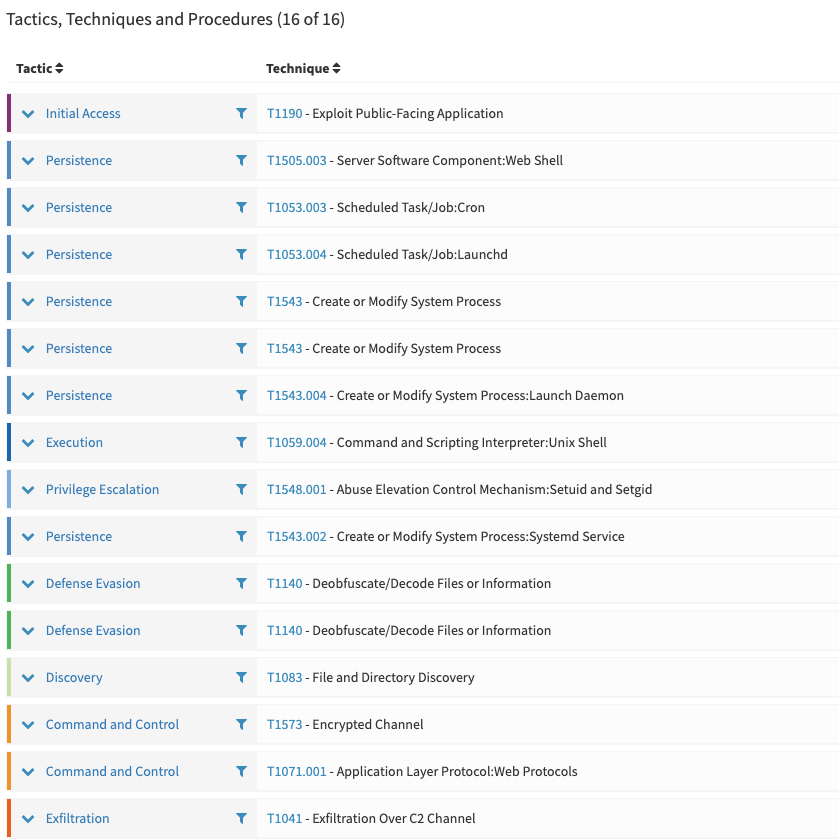
Tactics, Techniques & Procedures, with MITRE ATT&CK
Supporting MITRE ATT&CK framework is one of the feature that has been postponed many time from TheHive. It’s a no brainer feature that any blue team oriented product must include.
In TheHive 4.1, we allow:
Importing the official MITRE ATT&CK attack patterns collection as defined in https://github.com/mitre/cti. In this version support the entreprise catalog, but the future goal is to allow managing multiple catalogs in a misp-galaxy-like manner.
Defining TTPs associated with TheHive Cases
Attack Pattern management
From the administration page, any user with managePattern permission is able to have access to a page where patterns can be imported, filtered, viewed.
Import attack patterns
Attck Pattern management page
Case TTPs
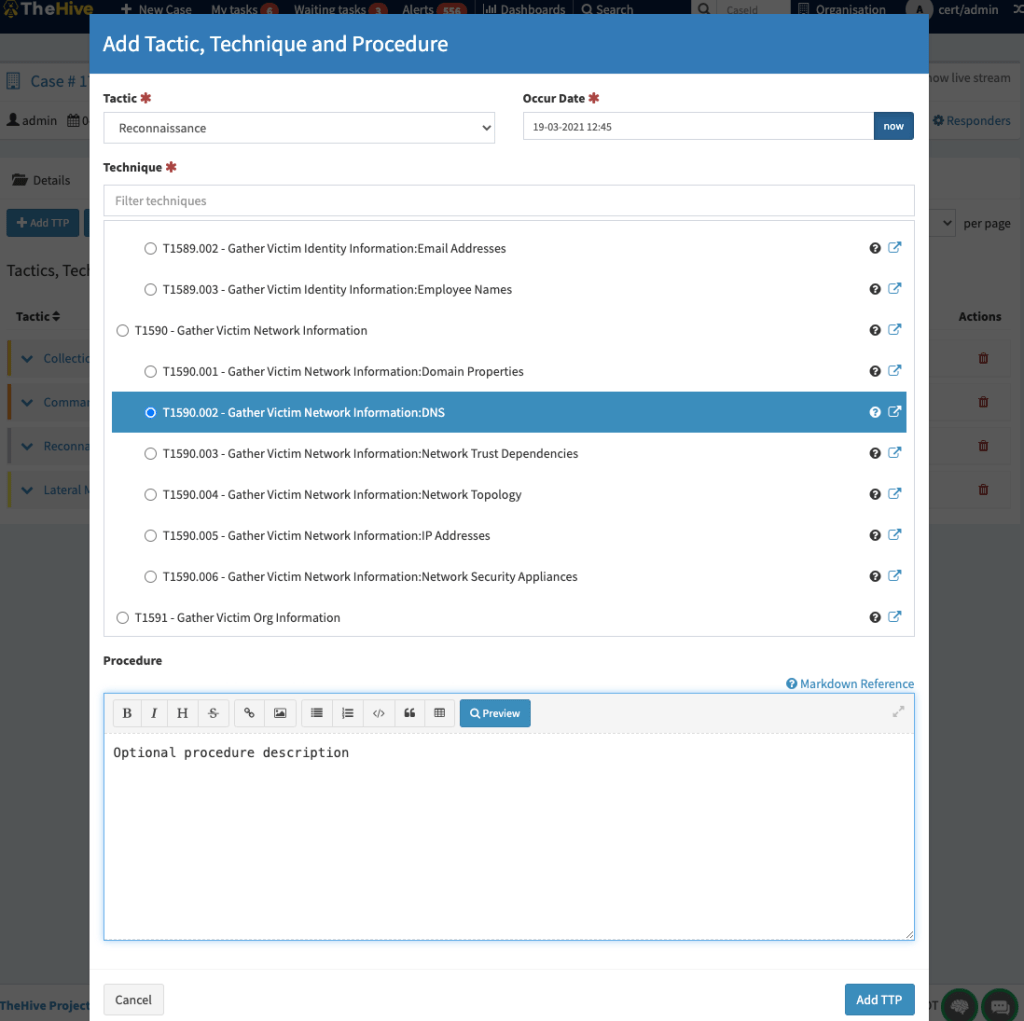
In addition to Tasks and Observables, in TheHive 4.1, you can associated TTPs to your Cases. TTPs objects are defined by:
A tactic
A technique or sub-technique
An occur date
An optional procedure description
Add a TTP to a Case
The Case TTPs are displayed in a dedicated tab on the Case details page, the same way as Tasks and Observables, with filtering and sorting capabilities.
This screenshot, showcases the tactic colours we use, thanks to Paul Tol’s blogpost
Case list TTP related improvements
One more feature: Case list now show the number of TTPs associated with each Case, with a link to the TTPs list page.
Case overview
Customise date and time
Since the very beginning, TheHive displays dates with the Month-Day-Year format. After 5 years, you can now customise the way you want date and time be displayed in all views of the UI.
This can be configured at the Organisation level, by defining the preferred format in the UI Configuration view. This required a user with org-admin profile or any profile with manageConfig permission.
UI Configuration view
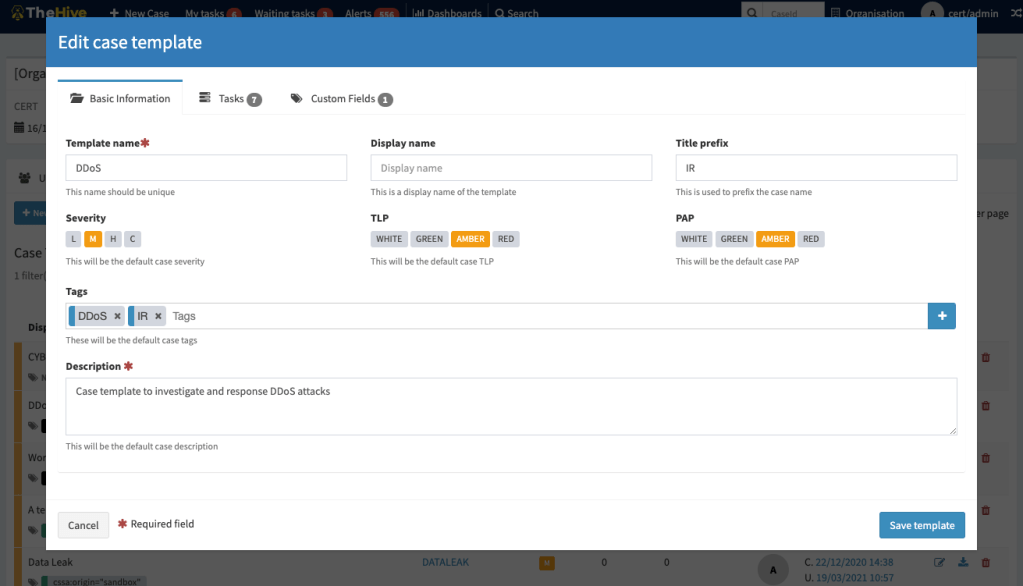
Improved Case templates management
Case template management UI has been rewritten to allow more capabilities, required when you start having a growing number of templates:
Filtering
Sorting
Display dates
Display number of tasks and custom fields
Case template management UI
Case template editing UI
Case merging
This is a feature that has been removed from TheHive 4.0 as it required a design update to take into account the multi-tenancy support.
In TheHive 4.1, case merging has the same UI:
Go to a case details page
Click merge
Select the case to merge data into
Validate
The difference in TheHive 4.1 is that, merging two cases, removes the originating cases, and create a new one with all the merged data.
Platform status page
This feature aims to help understand the issues related to TheHive health status. It contains details about:
database schema version
status of database indexes
status of database integrity checks
It also allows:
exporting a JSON report of the health status including more details then what is displayed on the UI
reindexing the database
triggering the database integrity checks
This page is available to super admin users and contains cross organisations data
Platform status
Webhook authentication options
In TheHive 4.1, you can define authentication configuration for your Webhooks. For more details, please refer to the documentation website
KNOWN ISSUE: the auth property in Webhook definitions, in application.conf file is REQUIRED, so if your webhook doesn’t need authentication, then just add
auth: {type: "none"}
for each Webhook definition
Updating from TheHive 4.0
Due to the new database indexation feature, updating from 4.0.x requires some attention. Depending on your type of installation – standalone server or cluster – your setup will need to be upgraded accordingly.
On standalone servers, you will have to define a new local folder to store indexes;
For a cluster, you will need to locate an Elasticsearch instance to use it as index.
Finally, update the /etc/thehive/application.conf configuration file, install the new version of the application and restart the service.
more detailed information regarding this update can be found here:
Indexes related to existing data will be created at the first start after the update to TheHive 4.1.0. Depending on the size of your database, this process can take a long time.
Upgrading from TheHive 3.x
If you are still using TheHive 3.x and want to migrate to TheHive 4.1, then you need to take a look to the following supported paths:
If you starts using TheHive with this version, we recommend having a look at our documentation site, and particularly to the installation and configuration section which is up to date and contains all instructions to install & configure TheHive 4.1.0.
Docker
If you use TheHive as a docker container, you can refer to the Docker-Templates repository that has a TheHive 4 up-to-date docker-compose configurations.
After the first feedback received from the community on Discord and Github, we have put the coming 4.1.0 release of TheHive on hold to focus on what can potentially break Cortex v3.1.0 and TheHive v3.5.0 with the upgrade to Elasticsearch v7.11.x. Several questions appeared on our side:
How to fix the installation process ?
How to fix the upgrade process ?
As the update of an existing Elasticsearch database to 7.11.x makes the downgrade impossible after that, will our fix repair it ?
Good news: this is fixed with TheHive v3.5.1 and Cortex 3.1.1, and these versions will repair databases that have already been updated to ES 7.11.x.
The update to these new versions introduces new indexes, for Cortex (cortex_6), as well as for TheHive (the_hive_17).
If you plan to run a new installation for Cortex, just follow the installation guide;
If you want to update your setup, we recommend to follow this process:
Stop TheHive or Cortex
Stop Elasticsearch
Update Elasticsearch package
Restart Elasticsearch and ensure this is going well
Install TheHive 3.5.1 or Cortex 3.1.1 package
If you already updated Elasticsearch to version 7.11.x and faced potential breaks with Cortex or TheHive, follow the process described previously and you should regain access to your data.
Once updated, you should be invited to update the database:
Update Database after installing TheHive 3.5.1 or Cortex 3.1.1
Click on “Update Database” and you should then be invited to login. Everything should work fine after that.
As usual, we recommend making backups or a snapshot of the database before running the upgrade.
If you are running TheHive v3.5.0 and / or Cortex v3.1.0, the underlying database is Elasticsearch v7.x.
Elastic recently released two new versions: v7.11.0 and v7.11.1. After some initial feedback and investigations, we found that the new releases introduce changes that break the compatibility with our products – TheHive 3.5.0 and Cortex 3.1.0.
Therefore, please DO NOT upgrade your current database to Elasticsearch v7.11.x as no rollback is possible. Elasticsearch v7.11.x breaks the installation process as well as the update process.
If you are in the process of installing or updating to Cortex v3.1.0 or TheHive v3.5.0, you need to specify the exact working version of Elasticsearch to use:
For Debian packages: “apt install elasticsearch=7.10.2”
FOR RPM packages: “yum install elasticsearch-7.10.2-1”
We are currently running deeper investigations and are planning to release updated versions as soon as possible for Cortex v3.1.0 and for TheHive 3.5.0.
Dear community, the new year has brought us another opportunity to build new features in your favorite Security Incident Response Platform, TheHive. We wish you a cheerful new year ahead and we thank you for being beside us all these years.
Last week, we released TheHive 4.0.4 and TheHive4py 1.8.1, and here is the official announcement including the details of the new features.
These releases focused on adding more capabilities to play with alert observables and give more flexibility when building alert feeders.
The major change in TheHive 4.0.4 is related to alert management. In TheHive 3, alert observables were included in the alert as an array of observable objects, and not as independent objects with links to the alert itself. This data model made alert observables CRUD operations, a bit challenging.
TheHive 4 has a better design for this, and alert observables have their own existence, and can be added/updated and deleted independently from the alert object.
This new design allows adding dedicated API endpoints to:
Add an observable to an existing alert;
Update the data of an existing alert observable;
Delete an observable from an alert.
Those APIs are not used by the user interface for now.
New Alert properties
This release introduced a new property called `importDate`. It represents the date at which an alert has been merged into a new/existing case. This property is then used to:
Allow filtering the alert list, for example: “List the alerts merged today”
Display the duration between the alert creation and its merge into a case.
Alert list showcasing alert importDate
This new property is of course available on the dashboard creation UI as a date field, among others:
imported: true if the alert has been merged
`handlingDurationInSeconds`: number of seconds before importing an alert
`handlingDurationInMinutes`: number of minutes before importing an alert
`handlingDurationInHours`: number of hours before importing an alert
`handlingDurationInDays`: number of days before importing an alert
To showcase the mentioned new properties, here are some screenshots:
importDate field used on a line chart as date field for x-axisSimple line chart using the imported filterDashboard including two charts using the newly introduced alert fields
What’s new in TheHive4py
The 1.8.1 release of TheHive4py mainly focuses on adding support to the new alert APIs introduced by TheHive 4.0.4. It comes with 3 new functions:
`create_alert_artifact` to allow developers adding a new artifact to an existing alert
from thehive4py.api import TheHiveApi
from thehive4py.models import Tlp
THEHIVE_URL = 'http://127.0.0.1:9000'
THEHIVE_API_KEY = '**YOUR_API_KEY**'
api = TheHiveApi(THEHIVE_URL, THEHIVE_API_KEY)
# Instanciate a new domain artifact
artifact = AlertArtifact(dataType='domain', data='malicious-domain.tld', ignoreSimilarity=True, ioc=True)
api.create_alert_artifact(ALERT_ID, artifact)
# Instanciate a new file artifact
artifact = AlertArtifact(
dataType='file',
data='malicious-file.exe',
ignoreSimilarity=False,
ioc=True,
sighted=True,
tlp=Tlp.RED.value)
api.create_alert_artifact(alert_id, artifact)
`update-alert-artifact` to allow updating the data of an existing alert artifact:
from thehive4py.api import TheHiveApi
from thehive4py.models import Tlp
THEHIVE_URL = 'http://127.0.0.1:9000'
THEHIVE_API_KEY = '**YOUR_API_KEY**'
api = TheHiveApi(THEHIVE_URL, THEHIVE_API_KEY)
# Create a new domain artifact
artifact = AlertArtifact(dataType='domain', data='malicious-domain.tld', ignoreSimilarity=True, ioc=True)
response = api.create_alert_artifact(ALERT_ID, artifact)
# Update its tlp, sighted and ignoreSimilarity flags
artifact_data = response.json()[0]
artifact_data['tlp'] = Tlp.RED.value
artifact_data['sighted'] = True
artifact_data['ignoreSimilarity'] = False
new_artifact = AlertArtifact(json=artifact_data)
api.update_alert_artifact(artifact_data['id'], new_artifact, fields=['tlp', 'ioc', 'ignoreSimilarity'])
`delete_alert_artifact` to allow removing an existing artifact from an existing alert
from thehive4py.api import TheHiveApi
THEHIVE_URL = 'http://127.0.0.1:9000'
THEHIVE_API_KEY = '**YOUR_API_KEY**'
api = TheHiveApi(THEHIVE_URL, THEHIVE_API_KEY)
# Delete alert artifact
api.delete_alert_artifact(ARTIFACT_ID)
Note that these new three methods are only available when using TheHive4py with TheHive 4.0.4+
This year is coming to an end. It’s a new opportunity to our team to release a new version of your favorite free and open source incident response platform, TheHive. We don’t aim to bother you during your Xmas holidays, but we thought of those who will be in front of their screens during the years’ last days.
Today, we announce the release of 4.0.3 that comes with some interesting enhancements and bug fixes.
What’s new?
The major features added in this release are:
improvement of the task management capabilities for collaboration, by adding a new flag called “Action Required”
review and improvement of the implementation of MISP synchronisation filters
new API capability to allow searching for Alerts per observables
new S3 provider and configuration for file storage (observables and task log attachments)
Require an action on a task
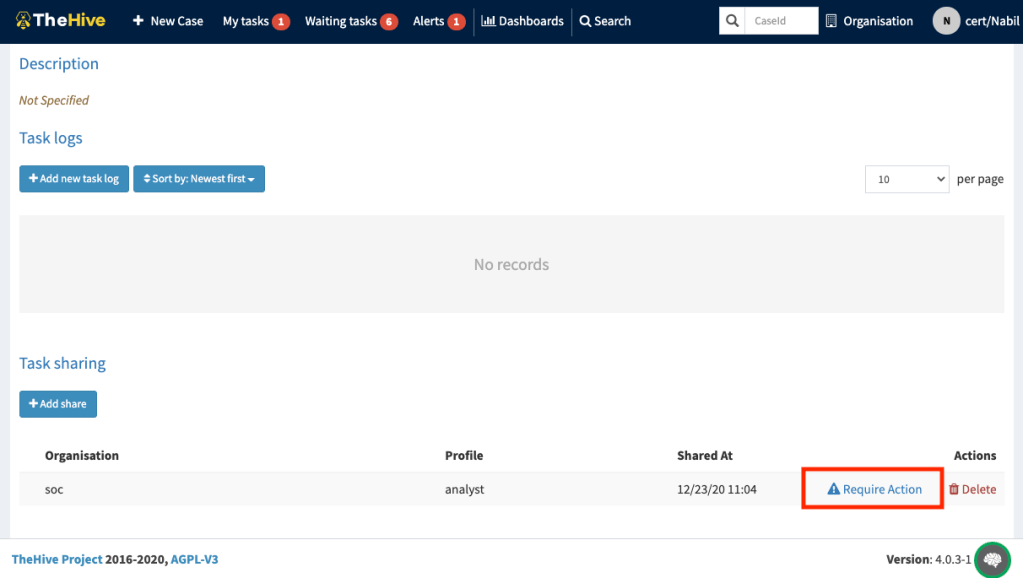
This feature is useful for collaboration to allow a master team requiring actions from the teams it collaborates with. Let’s explain it using a concrete example. Imagine a TheHive instance defining two organisations: SOC and CERT, both of them working on a Case led by the CERT team who is the owner of the Case.
For one of the tasks, the incident handler from the CERT team needs an action from the SOC team on a Task called “Gather evidences or IOC”. In the Task’s details page, at the “Sharing” section, for each “Share”, a new button “Require Action” is displayed. It allows any user with `manageTask` permission to enable the flag for the specific organisation for that specific Task.
The incident handler can also require an action from his team members.
Task details, Require Action from its own teamTask details, Require Action from another team
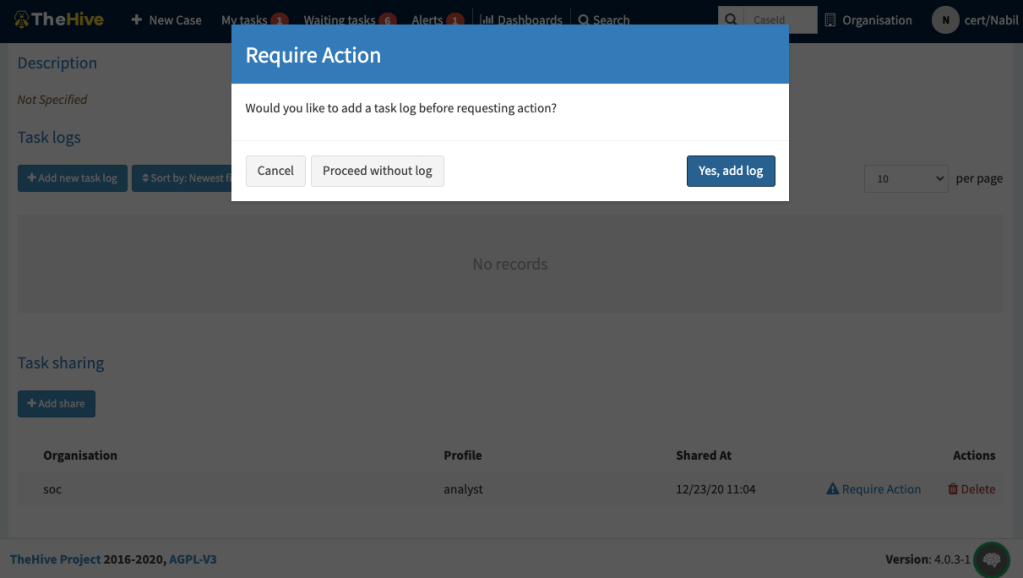
When the user clicks the “Require Action” button, TheHive asks if a Task Log needs to be added to the Task, to explain the required action. The user can proceed without adding a Task Log
Require Action confirmation dialog
If the user clicks on “Yes, add log”, a dialog is displayed asking the user to type a Task Log message and optionally add an attachment:
Add Task Log dialog
Once confirmed, the action is completed and the Task is marked as requiring action from the right team.
Action required from the SOC team on the “Gather evidences or IOC” Task
This feature comes not only with these Task related buttons but also includes some features for Case and Task listing pages, including filtering: its easier to list the cases where at least one task is still requiring an action from a team:
List of cases requiring actions
When navigating to the Task list, the user can easily see which Task needs an action:
Task list, filtered by the action required flag
When a user accesses a Task that is marked as requiring an action, the Task details page displays a warning message, with a “Mark as Done” button, that when clicked, confirms the completion of the required action:
Action Required warning message
When clicked, the “Mark as Done” button goes through the same confirm dialog as described above, allowing to optionally add a Task Log.
Review MISP filters configuration
TheHive 4.0.3 has reviewed and improved the performance of the MISP synchronisation services and added a new config to whitelist events by organisation, not only by tags. Below is a non exhaustive configuration of a MISP server, where the `whitelist.organisation` filter is used:
play.modules.enabled += org.thp.thehive.connector.misp.MispModule
misp {
interval: 1 hour
servers: [
{
name = "local" # MISP name
url = "http://localhost/" # URL or MISP
auth {
type = key
key = "***" # MISP API key
}
...
# Organization and tags
whitelist {
organisation = ["good organisation"]
# tags = ["tag1", "tag2"]
}
}
]
}
Search for alerts by observable conditions
In TheHive 3, Alert observables are stored within the Alert data, not as un independent piece of data, and querying them is not possible through the `_search` APIs and the Query DSL.
In 4.0.3 this limitation has been removed, allowing querying an alert with conditions on it’s child observables.
Using TheHive4py, the following code is now possible:
import json
from thehive4py.api import TheHiveApi
from thehive4py.models import *
from thehive4py.query import *
THEHIVE_URL = 'http://127.0.0.1:9000'
THEHIVE_API_KEY = 'API_KEY'
api = TheHiveApi(THEHIVE_URL, THEHIVE_API_KEY)
# Define the query
query = And(
Eq('source', 'THEHIVE-PROJECT'),
Eq('severity', Severity.MEDIUM.value),
Child('alert_artifact', And(
Eq('dataType', 'hash'),
Eq('data', 'A_HASH_VALUE')
)),
Like('title', '*MALSPAM*')
)
# Search for alerts
response = api.find_alerts(query=query, range='all')
# Print
print(response.json(), indent=4)
The code snippet above, searches for Alerts of with:
source='TheHive-Project'
severity=medium
title including the word “MALSPAM”
having a specific `hash` observable
S3 storage support
File storage is used in TheHive to store attachments. TheHive now supports a new type of storage in addition to hadoop and local file system: Amazon S3.
S3 storage provider can be configured by specifying endpoint, region and credentials. The settings must be located in the provider section, in application.conf:
If you are updating an existing instance of TheHive 4.0.0, ensure to read the installation guide. Since our recent release of TheHive 3.5.0, we updated our repositories. The codename of repositories containing all new released packages is now named release, instead of stable. So update your apt or yum repository file.
TheHive4py 1.8.0 is finally released. During the last 5 months, the team was busy working on TheHive and Cortex but today, it’s time to unveil the biggest milestone of TheHive’s official python API client.
TheHive4py official documentation website
1.8.0 contains 31 Github issues including 17 contributions for which, we would like to thank all the community members who helped shaping the release.
TheHive4py is getting a bit hard to maintain because of the backward compatibility constraints introduced by TheHive 3 and 4 versions. TheHive 4 also introduces new features that are not available in TheHive 3, and this makes it challenging to serve both versions with the same code base.
TheHive 4 has also its dedicated and optimised APIs (read APIs v1), and those are not used by TheHive4py, which is still relying on APIs v0 of TheHive 4.
Anyways.
What’s new?
1.8.0 release introduced a significant number of new methods and changes:
attachment download support for files (by id), observables and task log attachments
alert merge into case
alert delete
case task delete
case task log search
task log search
support to alert similarity in fetch
case observable search method
case observable fetch method
case observable delete method
support to in memory files when calling APIs evolving attachments
Below, we will highlight the major features other than the self explanatory newly added methods.
New version parameter
This change is important and required for developers using TheHive4py to play with a TheHive 4 instance. the `version` parameter has been introduced to allow fine tune access to features available on TheHive 4 and not in TheHive 3, like for `alert.extrnalLink` field.
The version is set by default to Version.THEHIVE_3.value, which means version 3.
from thehive4py.models import Version
# Init an API client for TheHive 4
api = TheHiveApi(THEHIVE_URL, API_KEY, version=Version.THEHIVE_4.value)
Add support to ignoreSimilarity field
This capability has been introduced by TheHive 4.0.1 release. It allows setting an `ignoreSimilarity` flag at the case and alert observable level. When set to True it tells TheHive to ignore the observable from any similarity computing.
So, if you need to create an alert with an observable you would like to skip when running the similarity algorithm, then, you need to set ignoreSimilarity to True
Here is an example that creates and alert with an observable to be ignored for similarity:
import uuid
from thehive4py.api import TheHiveApi
from thehive4py.models import Tlp, Pap, Alert, AlertArtifact
sourceRef = str(uuid.uuid4())[0:6]
# Prepare the Alert object
alert = Alert(title='Sample alert - ID {}'.format(sourceRef),
tlp=Tlp.AMBER.value,
pap=Pap.AMBER.value,
tags=['TheHive4Py'],
description='Sample alert for the blog post',
source='dev',
type='script',
sourceRef=sourceRef,
externaleLink='https://some-web-site/alert/{}'.format(sourceRef),
artifacts=[
AlertArtifact(
dataType='domain',
data='dl.some-web-site.com',
tlp=Tlp.WHITE.value,
ioc=True,
sighted=False,
ignoreSimilarity=True
)
])
# Init an API client instance
api = TheHiveApi(THEHIVE_URL, THEHIVE_API_KEY, version=4)
# Create the alert
response = api.create_alert(alert)
Note that the same option is available for Case observables during creation and update:
# Set an observable as ignorable
api.update_case_observable(
observable_id,
{"ignoreSimilarity": True},
fields=['ignoreSimilarity']
)
Support in-memory files
Old versions of TheHiv4py required existing files when dealing with attachments. For example, to create a file case observable, the corresponding file has to be already stored on the file system before calling the `create_case_observable` method.
This release allows using files from memory and not relying on file paths. So you use, for example, an API to download a file and you want to store that file as observable, you can use the new feature of TheHive4py, as below:
from thehive4py.models import Tlp, Pap, Alert, CaseObservable
# Say you have a method to get a screenshot
file = get_screenshot()
# Prepare the observable
observable = CaseObservable(
dataType='file',
data=(file, 'screenshot-{}.png'.format(int(time.time())*1000)),
tlp=Tlp.WHITE.value,
pap=Pap.GREEN.value,
tags=['category:screenshot']
)
# Create the observable
response = api.create_case_observable(case_id, observable)
# Close the file object
file.close()
Note: closing the file object is still required. We will handle closing the files during the upcoming releases.
Attachment download features
The new methods introduced by 1.8.0 release and related to attachment download, light some interesting TheHive APIs up.
Did you know TheHive has APIs to download existing file from the datastore? Do you know how does TheHive store files?
Well, when a file is uploaded to TheHive as case observable, alert observable or case log attachments, the file is stored in the DataStore and is given an ID that can be used in two APIs:
`/api/datastore/{attachment_id}`: downloads the file content
`/api/datastorezip/{attachment_id}`: downloads the file content as zip password protected file, and the password is the one defined in application.conf (defaults to `malware`)
In this release, we introduced methods to make these APIs available on TheHive4py.
Download an attachment by its ID
This method is useful if you know the attachment ID (could be an alert file observable for exemple, in TheHive 4)
# Download an attachment by a known id
response = api.download_attachment(
attachment_id,
filename='screenshot.png',
archive=False
)
# Save the attachment to disk
f = open('./{}'.format('screenshot.png'), 'wb')
f.write(response.content)
f.close()
Download an attachment of a task log
This method allows downloading the attachment of a given task log object, identified by its ID
response = api.download_task_log_attachment(log_id, archive=False)
f = open('./{}'.format('screenshot.png'), 'wb')
f.write(response.content)
f.close()
If the task log doesn’t have an attachment, this methods throws an exception.
Download a file attachment of a file observable
This methods allows downloading a file observable, and forces protecting it as password protected zip archive
response = api.download_observable_attachment(observable_id)
f = open('./{}'.format('observable.png.zip'), 'wb')
f.write(response.content)
f.close()
If the observable is not a file, this methods throws an exception.
Documentation
As you might know, with the 1.7.0 release we released a documentation website for TheHive4py where all the methods are documented. Donc hesitate to refer to it for more details: https://thehive-project.github.io/TheHive4py
Updating/Installing
To update your existing package to version 1.8.0:
$ sudo pip install thehive4py --upgrade
Got a question?
If you encounter any difficulty, please join our user forum, contact us on Discord, or send us an email at support@thehive-project.org. As usual, we’ll be more than happy to help!
Today, our public community has strong foundations and keeps growing as we welcome new users and organisations wishing to start their journey with TheHive Project. We can count on an amazing number of trusted and invested users willing to share their knowledge and help newcomers (the current Gitter channel is mostly self-managed). The GitHub issue highlighted several key improvements we could work on to provide a better chat experience to our community:
offering different channels, for different products to handle more targeted questions
implementing new roles like moderators and trusted-users
creating a channel for announcements
creating channels for contributions, automation
creating channels for languages other than English
listening to our member’s requests to improve the community server
We truly wish to enhance the chat experience of all community members, whether they join the conversation to ask a question, share their experience or help others troubleshooting an issue.
Why Discord?
Let us share a story.
TheHive Project’s core team first used Slack as its main private chat and communication tool. Slack is fine but we had some frustrating experience with it (ex: limited search history). We then moved to Keybase which is still our daily internal chat platform. Although we are satisfied with Keybase, we felt the onboarding experience might be a little too intense for some users.
So we decided to have a look at Discord, which was initially designed for gamer, allowing text chat, video, voice calls and screen sharing. Discord has great mobile apps too, in addition to those for web and desktop. And it’s really fast! It’s also getting a strong footprint with open source projects.
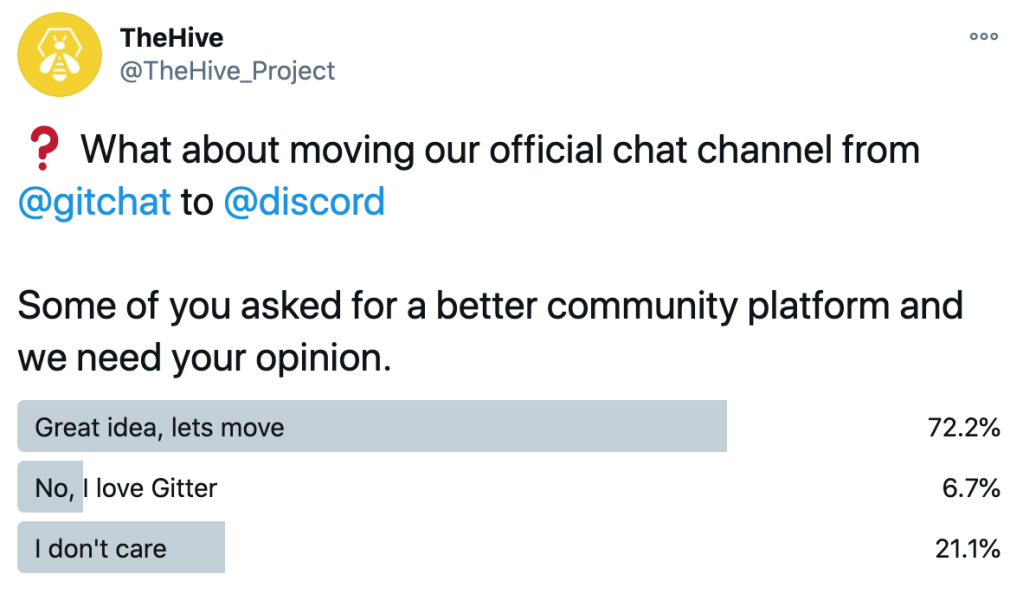
Last week, we posted a poll on Twitter about the move, and here are the democratic answers:
Twitter poll about Discord vs. Gitter
This confirmed our impression, so let’s do it.
How to join?
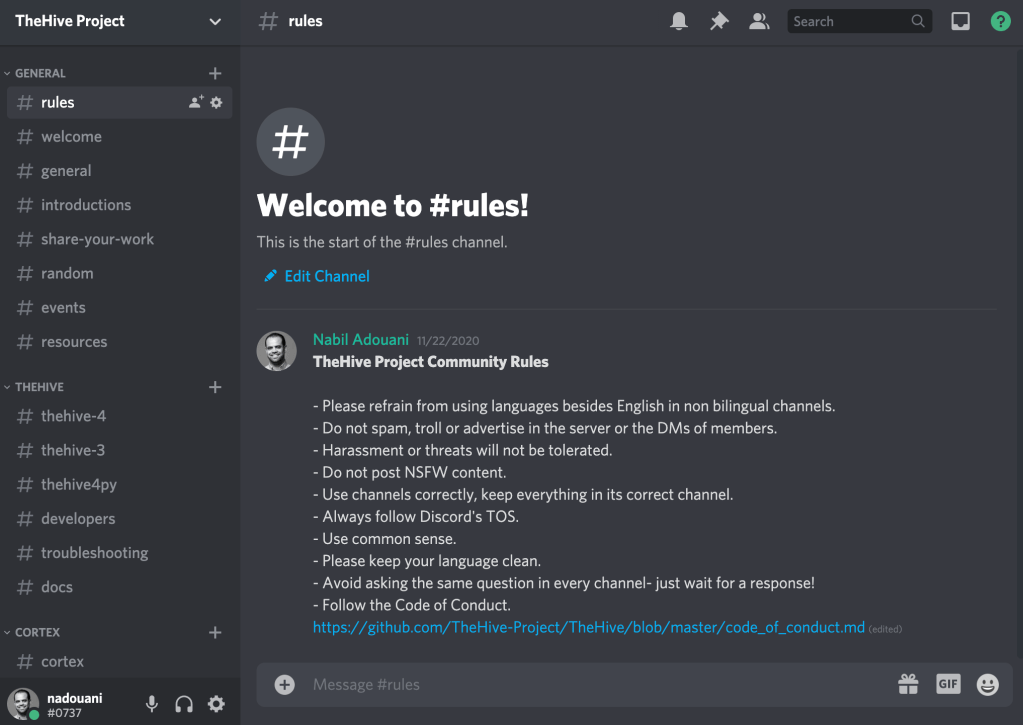
It’s easy peasy, here is the link Join our new Discord based community. It requires a Discord account with a valid email address (which is the lowest requirement). You will be welcomed with a screen that reminds the rules and code of conduct.
Welcome screen
Once registered:
If you wish to introduce yourself, you can share your story with us through the `#introductions` channel.
If you wish to share something you built in top of our products, your can do it in the `share-your-work`
If you need a new channel dedicated to your language, you can just ask for it or reach any core member or moderator
Community rules
What’s next?
We hope the current 1k+ users registered in Gitter will migrate to our new Discord platform. We will keep the light on in the Gitter channel for the time being, but we hope the Discord community will be the new land for all of you.
Last Friday, our team released a significant number of changes and fixes, improving TheHive 4. The community was very reactive and hurried to test it. Today we are announcing a patch release to fix annoying issues we decided to quickly patch: welcome to 4.0.2.
The major issue is related to Alert bulk merging which is part of the big refactoring of the Alert listing section.
Well, s**t happens, but as a gentlemen, we owe you a feature, or two 🙂
What’s new?
In addition to the Alert bulk merging issue, we fixed bugs related to:
Migration
Filtering observables by attachement attributes
Backward compatible APIs
Curious to read the detailed change log? Here your go.
TheHiveFS, do you remember?
It stands for TheHive File System, a feature we released with TheHive 4.0-RC1. In today’s milestone we are improving the security of this feature by adding a new user permission, required to have access to TheHiveFS features.
The newly created accessTheHiveFS permission is included by default in both org-admin and analyst user profiles.
Refined editable fields, for a better UX
In TheHive UI, editing objects relies on editable fields instead of dedicated form to edit objects. This means you can update a case title by clicking the Blue Pencil icon displayed when you mouse-over the case title for exemple.
In this release we refactored all the editable fields to provide a better user experience:
You no longer need to click just on the `Blue Pencil` icon to switch to edit mode, you just need to click on any value, for example the Case assignee field, or the Observable tags field:
Editable fields on mouse over events
Editable fields have now a `Clear` option, allowing users to unset the value of an attribute:
Editable custom fields can be set empty
This new improvement benefits to the custom fields sections in Case and Alert details sections, as showcased above.
Configurable layout of custom fields
In older TheHive versions, custom fields were displayed using a single column. Cases with big number of custom fields produced a long scrolling Case details pages, so we decided in TheHive 4 to use a 3-column layout to reduce the resulting scroll fatigue.
Now some users are complaining because of long custom fields values not being correctly displayed. So we decided to let users choose their preferred layout.
1-column layout to display custom fields in a Case details page2-columns layout
If you are updating an existing instance of TheHive 4.0.0, ensure to read the installation guide. Since our recent release of TheHive 3.5.0, we updated our repositories. The codename of repositories containing all new released packages is now named release, instead of stable. So update your apt or yum repository file.
Have you got a minute to let us know how you use TheHive ?
Back in July, we announced TheHive 4.0, the foundation for future releases of your favorite Open Source SIRP.
Today, we are pleased to deliver one of the biggest patch releases we’ve done so far, in terms of number of fixed issues: TheHive 4.0.1! Not only did we squash lots of bugs, we also included some cool improvements we didn’t want to hold until the next version.
A huge work has been accomplished to fix a backlog of bugs (thanks to the community) in several parts of the product:
Configuration;
API;
Dashboards;
Livestream;
Cases;
Alerts;
Observables;
Multi Factor authentication;
Active Directory authentication;
Export to MISP.
You can find details of the 80+ issues included in this milestone: Changelog file.
Wait, there is also new stuff:
Cases and Alerts similarity fine tuning;
Similar cases in Alert preview panel refined;
Filtering capabilities improvements;
New UI settings & options;
Custom fields in Case and Alert lists;
Statistics panel improvements;
API key in user settings page;
More migration tool options.
Cases and Alerts similarity fine tuning
In TheHive, correlation between Alerts and Cases, and between Cases themselves, is computed throughout their respective Observables:
A Case is considered similar to an Alert, if they have at least one common observable;
A Case is considered related to another Case, if they have at least one common observable.
In some situations, those relationships are undesirable when based on useless/meaningless observables.
Starting with TheHive 4.0.1, Observables are enriched with a new attribute called ignoreSimilarity, set to false by default. Now, when this attribute is set to true, an observable is simply not taken into account in the relationship between two cases, and is not involved in the similarity calculation, for Cases and Alerts.
This attribute is displayed alongside with the IOC and Sighted flags, in the Observables list – which has been tweaked for the occasion – as well as in the detailed view.
IgnoreSimilarity flag in the revamped Observables list
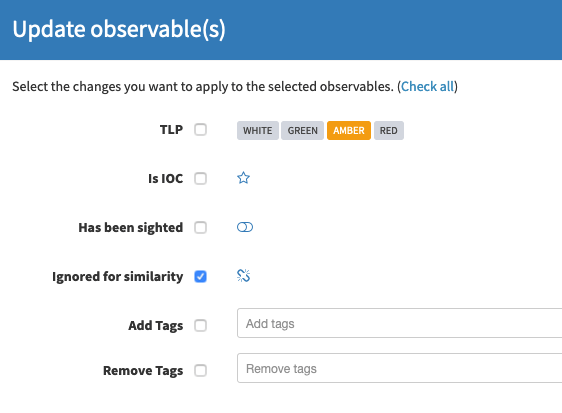
And you can also edit this for a set of selected observables.
Edit “Ignored for similarity”
Long story short, if you want to break a correlation, you just need to set the linking Observable‘s ignoreSimilarity flag to true.
Alerts and similar Cases
The attribute mentioned earlier is taken into account when correlating Alerts with existing Cases : the Similar Cases view in the Alert preview dialog.
Observables with ignoreSimilarity set to true will be ignored when fetching cases similar to the current Alert, whether it is in the Alert or the Case side.
A forthcoming update of thehive4pylibrary will allow to set this attribute in Alerts, along with many other new things.
The Similar Cases view has been thoroughly enhanced to provide more highlights facilitating alert triage and the merging of alerts into existing cases. First, a column named “Matched” has been added. It contains the list of observable dataTypes and the number of occurrences matching the Alert : this should be very useful to identify quickly what type of data has matched the alert content. A filter on this column has also been added.
And there are more refining capabilities in this view:
Sorting and Filtering on Title of Similar Cases;
Specifying a minimum observables rate that matches the Alert;
Specifying a minimum IOCs rate that matches the Alert.
Refining the Similar Cases view during Alerts triage
… And, above all, columns can now be sorted. With all these new capabilities, triage and merge Alerts in Cases should be easier.
Filtering capabilities improvement
In TheHive 4, filter forms have the same structure all over the product. Any improvement in the area, benefits to all the listing pages.
For example, in the alert similar cases tab, a new filter form has been included. You can quickly select the type of Cases you want to display, but also use the advanced rules and search criterias.
In this release, the filter component has new capabilities:
Date filter: now allows setting dynamic ranges instead of setting from and to fixed date values. Possible values are:
Today;
Last 7 days;
Last 30 days;
Last 3 months;
Last 6 months;
Last year;
Custom: allowing the old-fashioned way of setting date ranges.
Tag filter: Autocomplete is now enabled.
Advanced filtering for Similar Cases during Alert triage
Autocompleted tags when adding a filter
In TheHive 4.0.1, there is one more place that welcomed a filter form: the list of Alert observables in the preview dialog.
New Org level UI settings
UI configuration page is the place where TheHive adds new options to customise the behavior of the UI, for a given organisation. This is an area that will be expanded over time.
For this milestone, two new options have been introduced:
Allow merging Alerts in resolved cases;
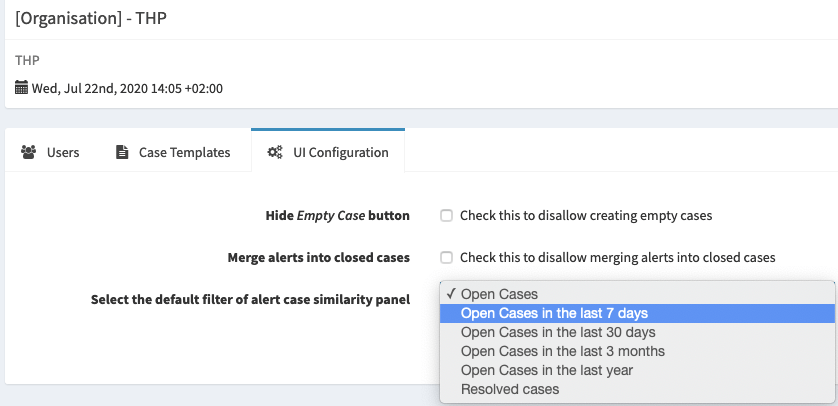
Default filter of Alert similar cases.
Default filter for Similar Cases in Alerts preview
The first one is self-explanatory and will hide the `Merge into case` button in the Alert similar cases section
The second one allows an administrator define, for an organisation, the default filter to apply to Alert similar cases view. For example: “show only potential similar cases created in the last 7 days and are still open”.
If during the triage, the filter has been updated by an analyst, the default filter cas be retrieved through Default filter option of the Quick Filters.
Retrieve default filter in alert similar cases
Custom fields in Case and Alert lists
“Damn, why I’m not able to see my custom fields in my cases list”, “It’s a shame I cannot filter my alerts with my custom defined properties”… We are pretty sure you said it, at least once.
Well, you dreamt of it, and here we go, we did it for Cases and Alerts
You will be able to see all the custom fields you defined in your Case Templates and propagated to your Cases;
Custom fields with undefined values are not displayed;
Custom fields are shown with respect of the order you define;
Clicking on a custom field, filters your lists using the selected value;
You can enable displaying the custom fields using the toggle button on the toolbar located on top of the filter form;
All those capabilities are available in Cases and Alerts views.
Custom Fields in Alerts list
New statistics view in Cases and Observables lists
The Stats view has been revamped to represent the statistics using both tables and shiny colourful donuts (not only for managers).
This improvement has been made in Cases, Observables and Alerts views.
New “Stats view” in Cases list
User settings
This feature has been initially introduced in Cortex and was missing in TheHive. All users can now access their API key, copy or update it, as long as an administrator created it first. No more API keys sent over emails or chat applications.
User settings with API key enabled
Migration
The migration assistant program has been updated with a few bug fixes and new filtering options. When migrating, you can now specify:
If you want to include or exclude Alerts generated from specific Sources or by their Type;
If you want to include Audit trails regarding specific objectType (case, case_task, case_observable …);
If you want to filter out Audit trails with specific actions (Update, Creation, Delete).
/opt/thehive/bin/migrate --help
[..]
--include-alert-types ,...
migrate only alerts with this types
--exclude-alert-types ,...
don't migrate alerts with this types
--include-alert-sources ,...
migrate only alerts with this sources
--exclude-alert-sources ,...
don't migrate alerts with this sources
[..]
--include-audit-actions
migration only audits with this action (Update, Creation, Delete)
--exclude-audit-actions
don't migration audits with this action (Update, Creation, Delete)
--include-audit-objectTypes
migration only audits with this objectType (case, case_artifact, case_task, ...)
--exclude-audit-objectTypes
don't migration audits with this objectType (case, case_artifact, case_task, ...)
So, you can migrate your data directly to TheHive 4.0.1.
However, please note that the migration tool does not support data from TheHive 3.5.0 yet. In short, you can only consider migrating you data from TheHive 3.4.0, 3.4.1, 3.4.2 or 3.4.4 to TheHive 4.0 or TheHive 4.0.1 for the time being.
If you are updating an existing instance of TheHive 4.0.0, ensure to read the installation guide. Since our recent release of TheHive 3.5.0, we updated our repositories. The codename of repositories containing all new released packages is now named release, instead of stable. So update your apt or yum repository file.
Have you got a minute to let us know how you use TheHive ?