We are proud and excited to annonce the availability of TheHive v4.1.0. This release is the new beginning of TheHive’s future, because all the upcoming features and enhancements will be based on this version, without the brakes.
4.1.0 is out after a significant work done during the last 6 months, interrupted by multiple events like:
- supporting ES 7 in TheHive 3 and Cortex
- supporting ES 7.11 in TheHive 3 and Cortex
- 5 patch releases of TheHive 4.0
- recent OVH datacenter incident (but this one was quickly fixed)
Our community is waiting for it, as we announced it will fix the performance issues that many of you were facing. The reason is that TheHive 4.0.x doesn’t include a database indexation component resulting on poor data fetching performance.
We are glad about this release, it includes tons of new features and improvements, across all the application.
The first and maybe, the main one, is the database indexation (#1731) that will significantly improve performance of queries such as lists, filters and sorting. As a consequence, you should experience a smoother browsing and usage of the application.
Amongst all other news features, we introduced:
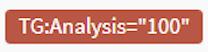
- Support for MISP taxonomies, in addition to custom tags and tag colour support;
- Support for Case TTPs specified by MITRE ATT&CK framework;
- Better and improved Case merging and deleting capabilities;
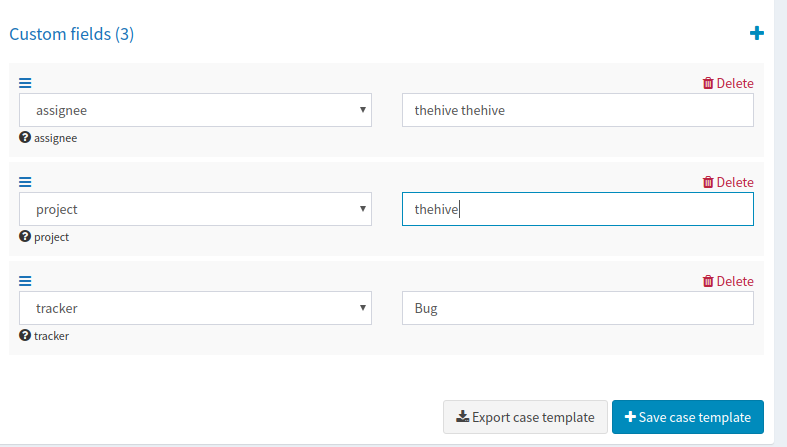
- A customisable date and time format
- A refined Case Templates management UI
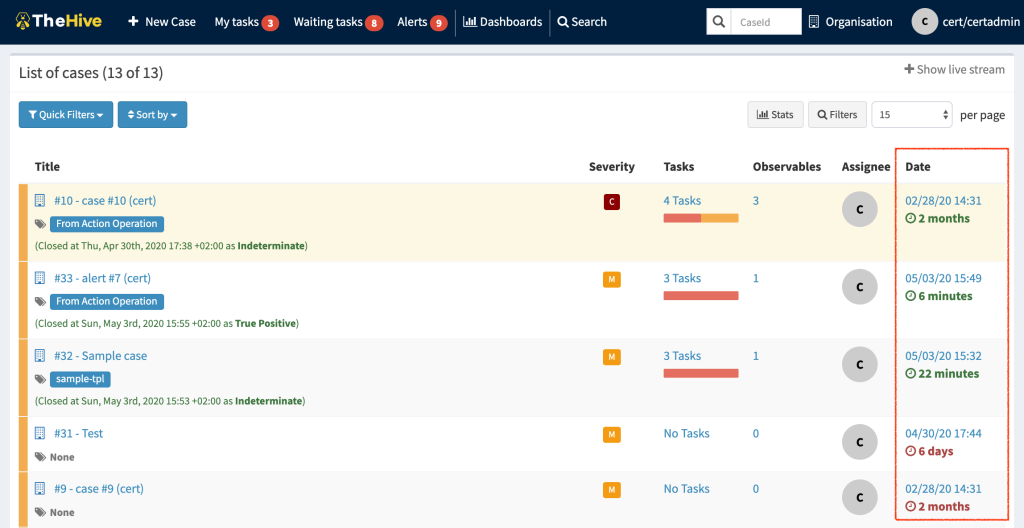
- Enhanced Case list UI with bulk actions
- Enhanced Task list UI with bulk actions
- A platform status page to get an overview of the platform health
- Support for migration from TheHive 3.5.1 to 4.1
- Support for authentication on Webhook endpoints
For those of you who want to know the full details, here is the change log
A word about the documentation
As you might know, TheHive has a documentation repository that includes content for TheHive 3 and TheHive 4, but the structure needs to be redefined. For that reason, we introduced a new documentation website that aims to be the single starting point of all the docs we produce for TheHive Projects’ products.
In the upcoming days, we will mark the old docs repositories as ARCHIVED and we will maintain the new docs repository.
To visit the new documentation website, go to
https://docs.thehive-project.org
More about the new features
Database indexation
Until now, we knew TheHive suffered from a performance issue with the database.
Technically, TheHive uses basic index mechanism embedded in JanusGraph. This indexes are simple to use and manage but they contain limitations. They only support equality lookups and cannot be used for sort (for example, this is not possible to simply look for cases with severity > LOW) . However, within TheHive, almost all lists – lists of cases, lists of alerts, tasks …- are sorted. So, getting a list means a scan of all the elements of the list, which have a heavy performance impact, particularly if the list is long.
In order to solve this issue, TheHive 4.1.0 comes with a new index engine, and indexes have to be stored outside the database. As a consequence you need to define and setup dedicated storage for these indexes.
- If TheHive is used in a cluster mode, all servers must connect to a common index engine, which can be in a cluster mode or not. In this case, a new component must be installed for index management. Elasticsearch should be used, only as an index engine. For clusters, Elasticsearch is not used like it was with TheHive 3.x when it stored data.
- If TheHive is used on a standalone server, Elasticsearch can be used, but a file based index engine – Lucene – can be preferred. The latter solution has less infrastructure impact – no component to install – and only requires configuration that indicate where index data is stored in the filesystem.
For more details about database indexing configuration, please refer to the documentation
MISP taxonomies support
TheHive 4 handles tags in a completely different way than TheHive 3, even if the APIs are still considering tags as simple strings. For example when you create a Case from TheHiv4py, you specify tags as a simple array of strings.
Behind the scene, TheHive transforms the tags into objects, with a namespace, a predicate and an empty value. For example if your create a case with a free tag src=mailbox, TheHive 4 creates a new Tag object as following:
{
"namespace": "_freetag",
"predicate": "src=mailbox",
"value": null,
"colour": "DEFAULT_COLOUR_FROM_THE_CONFIG"
}This is where we introduced the support of MISP Taxonomies, allowing admin users with `manageTaxonomy` permission, to import tags defined in machinetag.json format, from the “Administration > Taxonomies page”

Note: importing the full MISP taxonomies library can take some time (1 minute)
Once imported, you need to enable the taxonomies you need for use cases. All the taxonomies are disables by default. Enabling a taxonomy, make its tags available to all the organisations on the platform, so analysts can use the to tag Cases, Alerts, Observables.

Taxonomy tags can also bee used from any tag filter in Case, Alert and Observable lists:

Custom tags support
Custom tags or free tags, is the way we call free text tags associated with TheHive objects. Internally, custom tags are included into organisation related spécial taxonomy called `freetags`.
Custom tags are not shared across organisations, so existing users defining sensitive data in tags won’t suffer any data leakage issue.
In general, custom tags in TheHive are not supposed to user data and information. It’s not a best practice to use email adresses as tags. Custom fields are the right place for this type of data.
This topic needs a dedicated blog post, to share the best practices of using tags.
So, how do an org admin manage the custom tags? Well, TheHive 4.1 comes with a new UI section, under the organisation management page, allowing:
- Listing all the custom tags
- Filtering and sorting
- Updating custom tag values and colours
- Deleting custom tags
- Displaying custom tag usage (# of cases, # of alerts, # of observables and # of case templates)
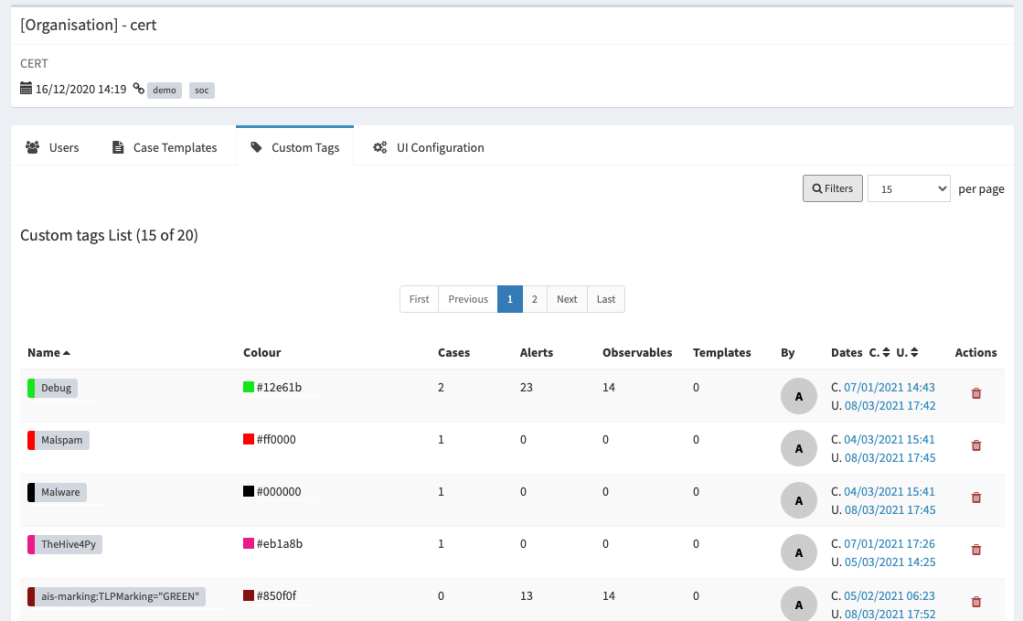
For users migrating from TheHive 3, all the existing tags are imported as custom tags
Tactics, Techniques & Procedures, with MITRE ATT&CK
Supporting MITRE ATT&CK framework is one of the feature that has been postponed many time from TheHive. It’s a no brainer feature that any blue team oriented product must include.
In TheHive 4.1, we allow:
- Importing the official MITRE ATT&CK attack patterns collection as defined in https://github.com/mitre/cti. In this version support the entreprise catalog, but the future goal is to allow managing multiple catalogs in a misp-galaxy-like manner.
- Defining TTPs associated with TheHive Cases
Attack Pattern management
From the administration page, any user with managePattern permission is able to have access to a page where patterns can be imported, filtered, viewed.
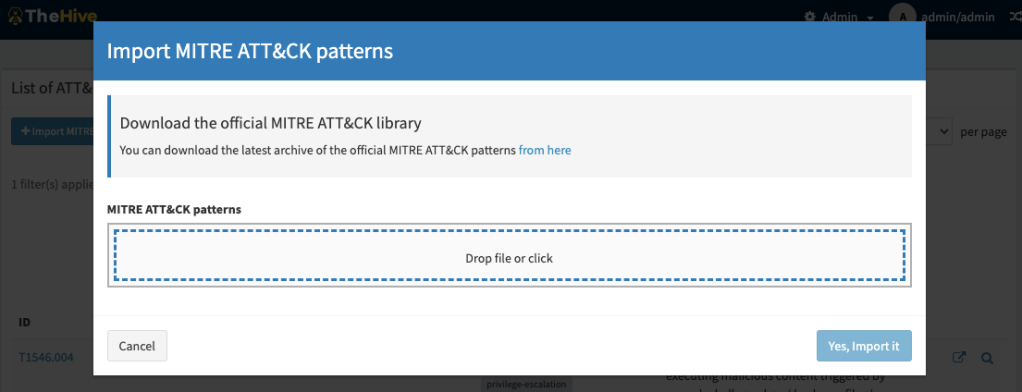

Case TTPs
In addition to Tasks and Observables, in TheHive 4.1, you can associated TTPs to your Cases. TTPs objects are defined by:
- A tactic
- A technique or sub-technique
- An occur date
- An optional procedure description

The Case TTPs are displayed in a dedicated tab on the Case details page, the same way as Tasks and Observables, with filtering and sorting capabilities.
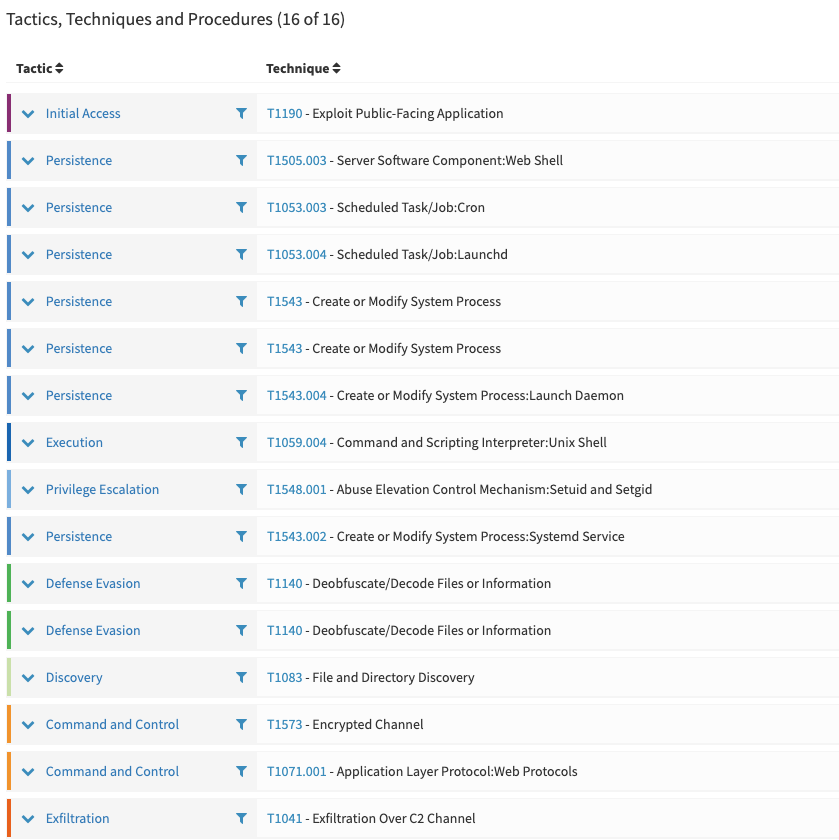
CAMPAIGN TARGETING
CENTREON SYSTEMS” by CERT-FR
This screenshot, showcases the tactic colours we use, thanks to Paul Tol’s blogpost
Case list TTP related improvements
One more feature: Case list now show the number of TTPs associated with each Case, with a link to the TTPs list page.

Customise date and time
Since the very beginning, TheHive displays dates with the Month-Day-Year format. After 5 years, you can now customise the way you want date and time be displayed in all views of the UI.
This can be configured at the Organisation level, by defining the preferred format in the UI Configuration view. This required a user with org-admin profile or any profile with manageConfig permission.

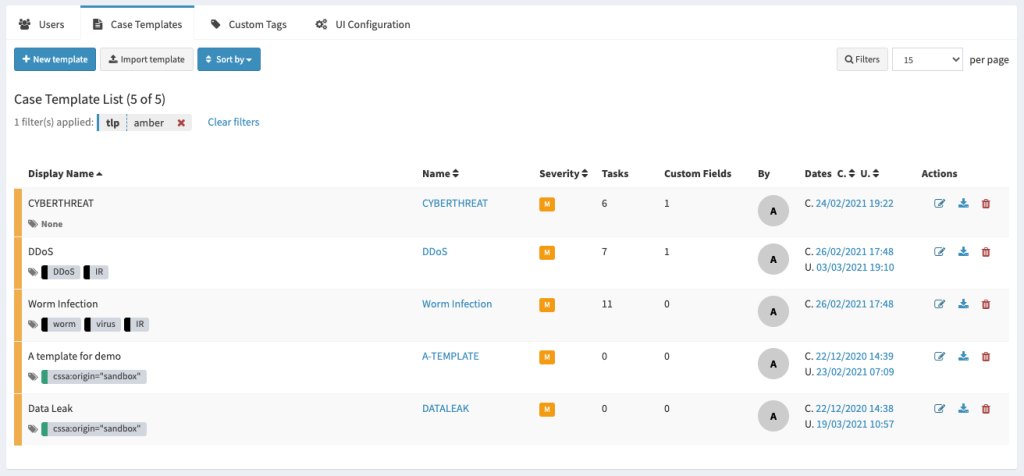
Improved Case templates management
Case template management UI has been rewritten to allow more capabilities, required when you start having a growing number of templates:
- Filtering
- Sorting
- Display dates
- Display number of tasks and custom fields

Case merging
This is a feature that has been removed from TheHive 4.0 as it required a design update to take into account the multi-tenancy support.
In TheHive 4.1, case merging has the same UI:
- Go to a case details page
- Click merge
- Select the case to merge data into
- Validate
The difference in TheHive 4.1 is that, merging two cases, removes the originating cases, and create a new one with all the merged data.
Platform status page
This feature aims to help understand the issues related to TheHive health status. It contains details about:
- database schema version
- status of database indexes
- status of database integrity checks
It also allows:
- exporting a JSON report of the health status including more details then what is displayed on the UI
- reindexing the database
- triggering the database integrity checks
This page is available to super admin users and contains cross organisations data

Webhook authentication options
In TheHive 4.1, you can define authentication configuration for your Webhooks. For more details, please refer to the documentation website
KNOWN ISSUE: the
authproperty in Webhook definitions, inapplication.conffile is REQUIRED, so if your webhook doesn’t need authentication, then just add
auth: {type: "none"}for each Webhook definition
Updating from TheHive 4.0
Due to the new database indexation feature, updating from 4.0.x requires some attention. Depending on your type of installation – standalone server or cluster – your setup will need to be upgraded accordingly.
- On standalone servers, you will have to define a new local folder to store indexes;
- For a cluster, you will need to locate an Elasticsearch instance to use it as index.
Finally, update the /etc/thehive/application.conf configuration file, install the new version of the application and restart the service.
more detailed information regarding this update can be found here:
https://docs.thehive-project.org/thehive/operations/update/
Indexes related to existing data will be created at the first start after the update to TheHive 4.1.0. Depending on the size of your database, this process can take a long time.
Upgrading from TheHive 3.x
If you are still using TheHive 3.x and want to migrate to TheHive 4.1, then you need to take a look to the following supported paths:
| Target version | Required source version |
| TheHive 4.1.x | TheHive 3.5.1 |
| TheHive 4.0.x | 3.4.x < TheHive < 3.5.1 |
For more details, please refer to the documentation website
How to install
If you starts using TheHive with this version, we recommend having a look at our documentation site, and particularly to the installation and configuration section which is up to date and contains all instructions to install & configure TheHive 4.1.0.
Docker
If you use TheHive as a docker container, you can refer to the Docker-Templates repository that has a TheHive 4 up-to-date docker-compose configurations.
How to report issues
Please open an issue on GitHub with the dedicated template for TheHive 4. We will monitor them closely and respond accordingly.
Running Into Trouble?
Shall you encounter any difficulty, please join our user forum, contact us on Discord, or send us an email at support@thehive-project.org. We will be more than happy to help!